




Creating future-proof Industrial Solutions–Architecture Verification & Static Code Analysis
In the world of industrial automation, systems are required to solve more and more complex tasks. As...
Watch video
Navigating the Future Landscape of Industrial Automation Excellence
Join experts from Bosch Global Software Technologies, Konecranes, and Qt Group as we explore the fut...
Watch video
How To Use QML in Qt6 | User Interface | #QtWS21
This talk will show how to best use the new CMake API for QML modules, declarative type registration...
Watch video
Webinar: The Contest for Al Dominance: Decoding Al & The Race for Tomorrow's Tech
In the ever-changing world of technology, discussions about artificial intelligence (AI) have become...
Watch video
Qt for MCUs on Renesas RA8-D1
Qt Group announces tech-preview support for Renesas RA8-D1 microcontroller platform, the industry’s ...
Watch video
Porting a Large Scale Non-Qt Legacy CAD Application to Qt/QML: The Good, The Bad, and The Ugly
Abstract: Over the last 3 years, we have been working on porting our large legacy CAD software (Alia...
Watch video
Qt Development for macOS: Tips and tricks with Lukas Kosiński | #QtWS23
Abstract: Dive into the world of Qt development for macOS with this insightful talk, designed to emp...
Watch video
Getting Qt to run on new MCU environments with Bruno Vunderl | #QtWS23
Abstract: Unlike desktop application environments that provide (more or less) stable APIs on how to ...
Watch video
Integration of UX Into HW/SW Co-Design Analysis Infrastructures with Andreas Aal | #QtWS23
Abstract Using virtual environments in flight and driving simulators is an established way to derive...
Watch video
Panel Discussion: Is Software Making the Lives of Developers Easier? with Kate, Kevlin, & Volker
Panel Discussion: Kate Gregory, Kevlin Henney, and Volker Hilsheimer
Watch video
Customer Case: Mercedes-Benz with Victoria Fischer | #QtWS23
Abstract: Mercedes Benz is using Qt to build its world-class MBUX, allowing pixels to be pushed at t...
Watch video
From Code to Influence: The Road to Staff Engineer at Sky with Jonathan Courtois | #QtWS23
Abstract In today’s tech landscape, the notion of progression often pivots towards management roles....
Watch video
Qt Roadmap with Volker Hilsheimer & Maurice Kalinowski | #QtWS23
Abstract: How does the roadmap of Qt Development looks like? What to expect in upcoming months? Qt C...
Watch video
Customer case: Konecranes with Eugenio Torrini | #QtWS23
Abstract: We were talking about containers way before Docker existed, we have modularity and reusabi...
Watch video
Trends in Product Creation - Open Software, Tools, and Frameworks with Tuukka, Volker & Aleksina | #QtWS23
Abstract: The evolution of the Qt Ecosystem, Open Software, Open Tools, and Open Frameworks. We will...
Watch video
Webinar: Shaping HealthTech: Data Security, Modernization, and Beyond
The healthcare industry is undergoing a rapid transformation as new technologies, regulations, and c...
Watch video
How to Seamlessly Migrate Qt from an MPU to an MCU
Learn how Qt for MCUs can help you whenever your embedded application needs real-time processing, op...
Watch video
Webinar: What's New in Qt 6.6
The release of Qt 6.6 is packed with many UI and backend development enhancements. Join our technica...
Watch video
Rev Up Reality with Qt Best-in-Class Real-Time Rendering Capabilities
Enjoy game-engine-like graphics on resource-constrained embedded systems. With its high-performance ...
Watch video
Webinar: Driving the Future - Key Trends Shaping the Automotive Industry
What lies ahead for the automotive industry? Which trends and technologies are shaping the landscape...
Watch video
High performing Qt GUIs on STM32 Microprocessors
Learn how to deploy Qt on top of STM32MP157 with a dedicated GPU and the STM32MP135 for simpler GUI ...
Watch video
Qt 6.5 LTS Technical Features Overview
In this webinar we will introduce you the main new features coming with the Qt 6.5 LTS releases. We ...
Watch video
SmartHome | Built with Qt
Transforming home appliances into smart-devices capable of helping users in their daily routines and...
Watch video
Top 5 UI/UX Trends Shaping the Future
In today's fast-paced digital landscape, creating exceptional user experiences is crucial for succes...
Watch video
Qt 6.5 LTS Release - Enabling stunning and immersive experiences
Take a look at a quick overview of what's new in the Qt 6.5 LTS Release with Product Director Mauric...
Watch video
Qt Quick Effect Maker - Smart Watch Demo
Take a look at the latest from the Qt Quick Effect Maker in this Smart Watch Demo. Read more.
Watch video
Porting a Large Desktop CAD Application to Qt
BricsCAD is a cross-platform desktop (linux/mac/windows) CAD application with over 20 years of histo...
Watch video
Insights Into Graphics Innovations at Infineon’s Traveo™ 2nd Gen MCU
The speech provides some insights into the graphic modules and features used at Traveo™ 2nd Generati...
Watch video
Working with Qt in a Regulated Industry
This talk discusses developing medical devices at GE HealthCare in a regulated environment, and the ...
Watch video
Qt Design Studio – Designers in the Development Cycle
Developing a 3D scene for limited hardware: this talk will try to showcase the benefits for designer...
Watch video
Taking 3D Content to the Next Level with Physics, Global Illumination, Reflections and Spatial Audio
Qt Quick 3D is a high-level Qt API for creating 3D scenes that can be seamlessly combined with 2D UI...
Watch video
KDE Eco: Achievements, Impact, and To-Do's
Given Free and Open Source Software's core values of transparency and user autonomy, FOSS has an edg...
Watch video
How Not to Design Reusable Components in QML
Reusable components are at the heart of QML and any other type of UI programming. The success of you...
Watch video
Qt World Summit 2022 Opening Address
In this opening keynote address, Juha Varelius, CEO will give an overview of what’s been happening a...
Watch video
Qt and WebAssembly Takes Client Development Mainstream to the Web | #QtWS22
Qt has made substantial investment in WebAssembly in recent years. Many developers and observers ini...
Watch video
Developing a Unified Mobile and Desktop App with Qt | #QtWS22
The distinction between mobile and desktop applications is becoming increasingly blurred. Convertibl...
Watch video
Integrating Custom Rendering Engine with QML Quick | #QtWS22
In this talk, we will take a close look at how to seamlessly integrate a fully custom OpenGL renderi...
Watch video
Hands-On Tour of Embedded Linux System Calls In Qt | #QtWS22
While Qt offers tremendous functionality in performing system level tasks in the framework via C++, ...
Watch video
ChargePoint EV Charging and Qt WebAssembly - Virtually Everywhere | #QtWS22
ChargePoint utilizes Qt+WebAssembly to provide an online simulation of our EV Charging UI using the ...
Watch video
Qt and C++20 | #QtWS22
When Qt 5.0 was released, it was the first version to require C++98 compliant compilers. Qt 5.7 then...
Watch video
How to Access Android API from QML With No Effort | #QtWS22
This talk will show how Spyrosoft is using the Qt Interface Framework and AIDL to expose Android API...
Watch video
Highlights from Qt Widgets and More | #QtWS22
This presentation is both for Widgets and QML developers! Qt Widgets and More is a YouTube series wi...
Watch video
Qt Bridge Plugins in Depth | #QtWS22
Qt Design Studio (QDS) helps you makes the leap from design to concrete UI. The Qt-Bridge plugin is ...
Watch video
Tips and Tricks for Testing Large Projects with the Qt Test Framework | #QtWS22
Building large-scale, feature-rich projects that run on multiple platforms poses many testing challe...
Watch video
The New Qt Quick Compiler Technology | #QtWS22
Since Qt 6.2, we have gradually phased in the new Qt Quick Compiler Technology. Using the overhauled...
Watch video
QML Hot Reload in Practice - How to Get More Productive with Code Reload | #QtWS22
Bringing a great User Experience for your product is hard. And often, we don't spend our time workin...
Watch video
Making Qt Quick Controls in Qt Design Studio from Figma Variant Components | #QtWS22
In this session, Brook will show how to setup a project consisting of a set of template files, based...
Watch video
Achieving Limitless Scalability
How to create sophisticated, user-friendly applications that work across multiple devices and operat...
Watch video
The iOS Style for Qt Quick Controls 2 | #QtWS22
Qt Quick Controls applications running on iOS haven't yet had a native-looking style, forcing develo...
Watch video
Migrating from QMake to CMake | #QtWS22
This talk will show you how to migrate existing qmake projects to CMake. It will also cover the usag...
Watch video
5 Reasons Why You Should Use the Latest Qt for Python | #QtWS22
C++ has evolved tremendously in the last decade in its quest to become a safer, more elegant languag...
Watch video
Handling Dates and Times in Qt & Making the Most of Qlocale | #QtWS22
This will be a 2-part presentation. Part 1: This talk will provide an overview of the date, time and...
Watch video
What You Need to Know to Collaborate Better Between Designers and Developers | #QtWS22
This talk will provide some tips based on the experience of a few of Qt's Technical Artists and Solu...
Watch video
The Latest on Qt Learning | #QtWS22
This talk will introduce you to the latest updates and plans on Qt Learning: Qt Educational Licenses...
Watch video
Qt Positioning in Qt 6 | #QtWS22
This talk will discuss the improvements that were made to the Qt Positioning module in Qt 6. It will...
Watch video
CMake and Qt. qt_add_qml_module in Practice | #QtWS22
The need to switch from qmake to Cmake has caused many Qt developers to have difficulty organizing t...
Watch video
In Small Packages: Starting from Scratch with Qt for MCUs | #QtWS22
In this talk we will build a simple Qt for MCUs GUI project from scratch with Qt Design Studio and Q...
Watch video
How Test Automation Can Improve Customer Satisfaction and Accelerate Time-to-Market | #QtWS22
Development costs and release frequencies increase, and you actually have less time for testing than...
Watch video
10 Years of Rimac In-vehicle Infotainment with Qt
From development kits and a one-man band building the first in-vehicle user interfaces, to series pr...
Watch video
16 reasons why companies love Qt
Learn more about Qt on our website: https://www.qt.io See why our customers love us as much as we lo...
Watch video
How to automate Qt GUI Tests
TALK: Automating Qt GUI Tests on Desktop, Web, Mobile and Embedded SPEAKER: Reginald Stadlbauer COMP...
Watch video
Built with Qt: 908devices reach markets faster and save resources with Qt.
The MX908TM is a multi-mission tool utilized by elite responders conducting chemical, explosive, pri...
Watch video
A 3D UI and a 2D UI - Same Code Base, Same Design {showcase}
Santtu shows you how you can develop a 3D UI for higher-end and a 2D UI for lower-end hardware with ...
Watch video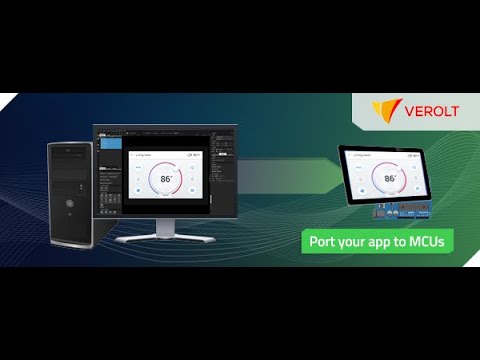
A Guide to porting Qt Quick applications to Microcontrollers using Qt for MCUs {On-demand webinar}
Qt for MCUs allows you to develop Qt applications that run on Microcontrollers. With the help of Qt ...
Watch video
A handful of how-to's on Qt Creator - Dev/Des 2021
www.qt.io https://www.qt.io/product/qt6 Alessandro Portale shares a handful of how-to's on Qt Creato...
Watch video
A Modern Ubiquitous Approach Across the Complete Product Family {On-Demand Webinar}
Covid-19 has device makers across all industries experiencing record-breaking demand. Home appliance...
Watch video
Accelerated 2D and 3D Graphics in Qt 6
www.qt.io Laszlo Agocs, Principal Software Engineer at The Qt Company takes a deeper look at the cha...
Watch video
Advanced 3D features - Dev/Des 2021
www.qt.io https://www.qt.io/product/qt6 With Qt 6, the Qt framework takes a step closer to 3D game e...
Watch video
Advanced session on Yocto & eLinux {Qt Virtual Tech Con 2020}
This hands-on advanced session on how to edit your B2Qt image and Yocto based Embedded Linux. Samuli...
Watch video
All the things you need in on Qt box, LASE Industrielle Lasertechnik
An easy-to-use framework, saving development time, and rapid UI prototyping with QML - what's not to...
Watch video
All You Need to Get Your App Done with Qt for Android | Tools | #QtWS21
This talk shows how to go about developing an Android app using Qt for Android. We'll cover differen...
Watch video
Amazon Web Services create ROBOT ARM CHALLENGE with MXNet deep learning and Qt {showcase}
This is an Interview and demo with Anton Chernov from Amazon Web Services. Anton shows off the Robot...
Watch video
Model-based HMI development using Qt
Discover the process to validate the whole system based on the mathematical models even before the h...
Watch video
Analyzing Dependencies with Dependency Walker
Learn how to analyze dependencies of your application to find a matching Squish for Qt package that ...
Watch video
Animations and Materials in 3D Scenes with Qt Design Studio
www.qt.io Filip Wasil goes over the basics of Qt Design Studio and how to use it to create a modern-...
Watch video
Augmedics Xvision project & live Q&A
Asaf Asban and Eliah Ninyo will give an intro to the Augmedics Xvision project – a combination of PC...
Watch video
Aurora Net: Sound Management and Monitoring System by dBTechnologies Built with Qt
Aurora Net boosts the management and monitoring of your sound reinforcement systems into overdrive. ...
Watch video
Automagically' turn your design into code - Dev/Des 2021
Ever dreamed about watching your design turn into development-ready code? Well, here’s your chance t...
Watch video
Automated Qt GUI Testing | Tools | #QtWS21
This talk shows how Squish GUI Tester can be used to design and execute cross-platform tests for Qt ...
Watch video
basysKom Showcases a Qt OPC UA HMI for Industrial Controllers
basysKom's Frank Meerkötter shows off an industrial HMI built with Qt Quick and Qt OPC/UA. Qt OPC UA...
Watch video
Be even more cross-platform with Qt for WebAssembly!
Qt for WebAssembly is a platform plugin that lets you build Qt applications for the web, with less s...
Watch video
Best Practices for Qt for MCU | Graphics | QtWS21
The talk will show you the best practices to have in mind when developing multi-threaded GUI applica...
Watch video
Best Practices for Qt on Mobile (iOS + Android) {Qt Virtual Tech Con 2020}
Whether you want to bring your existing Qt application to Mobile or develop an own Mobile-optimized ...
Watch video
Best Practices in Writing Applications in QML | User Interface | #QtWS21
This talk shows which rules you should follow to make your Qt Quick application a long-term success....
Watch video
Best Practices to Improve Your Embedded Product Experience {On-demand webinar}
Creating a great product experience means taking a human-centric approach to software design. Unders...
Watch video
Better products for Omicron Energy Built with Qt - with Sabariesh Ganesan
Find out how Omicron Energy developed a much better product than their competitors and saved a lot o...
Watch video
Addressing Medical and Industrial Challenges {On-demand webinar}
The QNX® Neutrino® and its safety variant, the QNX® OS for Safety, are widely regarded as safe and s...
Watch video
Boost development time for Embedded
Christian Feldbacher, CEO & Co-Founder of FELGO, discusses boost development for embedded device...
Watch video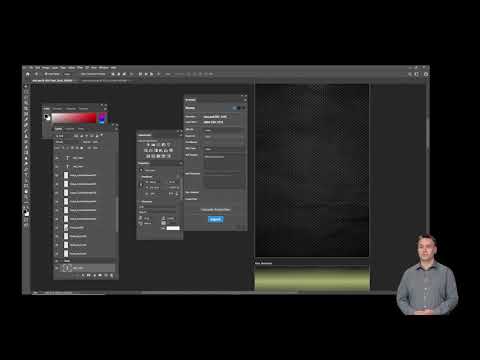
Bridging the gap between designers and developers
Thomas Hartmann, Senior Manager R&D, The Qt Company, talks about Qt Design Studio, Qt's 2D and 3...
Watch video
Bridging the gap between Developers and Designers - Live demo
When creating a working UI (user interface), there is often a disconnect between the Designer’s UI d...
Watch video
Bridging the gap between UX and development {On-demand webinar}
When you think of what makes a good app, our minds increasingly shift from a pure functionality to t...
Watch video
BrightONE 3D HUD for Automotive Built with Qt {showcase}
BrightOne's Piotr Szul shows off a cool new 3D heads-up display for an automotive instrument cluster...
Watch video
BrightONE's Gesture Control Demo on an Automotive HMI {showcase}
BrightOne's Piotr Szul shows how smooth gesture control on an automotive HMI built with Qt can be.
Watch video
Build Deep Learning Applications with Qt and Tensorflow Lite - Dev/Des 2021
Only a few decades ago it seemed impossible to automatically classify bird species in images, let co...
Watch video
Build your first 'Qt for MCUs' application
Qt for MCUs is a complete graphics framework and toolkit with everything you need to design, develop...
Watch video
Build your first WebAssembly application {Qt Virtual Tech Con 2020}
In this talk we'll take a look at how to get started with Emscripten and Qt for WebAssembly. This in...
Watch video
Building a Qt Application with Modern CMake and vcpkg
In this webinar, Alexandru will go through the process of building a Qt Quick Controls 2 application...
Watch video
Building an app with Qt for MCU on top of FreeRTOS {Qt Virtual Tech Con 2020}
Join this webinar to learn how to build an example application that uses M4/M7 cores where: M4 core ...
Watch video
Building Immersive Environments and UX with Qt Quick 3D | Graphics | #QtWS21
Modern 3D UIs are much more than just 3D objects floating around in empty space. This talk looks int...
Watch video
Built with Qt: AirServer Universal Mirroring Receiver
AirServer can transform a simple big screen or a projector into a universal screen mirroring receive...
Watch video
Built with Qt: AMD Radeon Software
Andrej Zdravkovic, Corporate Vice President Software Development and Graphics Platform Solutions at ...
Watch video
Built with Qt -AR & Non-GPU UI with KDAB
Qt Partner KDAB presents two demos at Embedded World 2017. Augemented Reality based on Qt 3D & N...
Watch video
Marine & Vehicle Automation: Digital Switching, BEP Marine CZone
Software Engineer, Jeremy Stott with BEP Marine Limited, a Power Products LLC Company, speaks to the...
Watch video
Built with Qt - Drone/Unmanned Autonomous Systems (UAV) Ground Control Station
"I have no hesitations recommending Qt Professional Services to anyone in terms of getting to market...
Watch video
Built with Qt - Embedded HMI development with basysKom
Qt partner basysKom presents their Qt based Embedded HMI Framework.
Watch video
Built with Qt: Esri ArcGIS Runtime SDK for Qt
The esri ArcGIS Runtime SDK lets you build native apps with ArcGIS and Qt. Integrate a wide range of...
Watch video
Built with Qt - Formlabs intuitive & connected 3D printing experience
Formlabs designs and manufactures pioneering desktop 3D printers, bringing innovative and sophistica...
Watch video
Gesture Controlled Qt Automotive Suite HMI, Partner brightONE
Qt Partner brightONE has used Qt Automotive Suite to develop a gesture controlled HMI. Use your hand...
Watch video
Built with Qt - Harman's Award-Winning Mini Cooper Cockpit
Harman won the reddot award for their HMI design on the Mini Cooper. The infotainment system and ins...
Watch video
Built with Qt: ISOBUS/CCI Smart Farming with KDAB
Smart farming is not just good for our planet, it's good business too! Competence Center ISOBUS, or ...
Watch video
Smart Agricultural Machinery Built with Qt: KDAB & AgBrain
For truly smart farming, the agricultural terminals need to allow operators to simply oversee and ha...
Watch video
LG Consumer Electronics - Built with Qt
LG’s innovative technologies, unique products, and cutting edge designs are built with Qt. We interv...
Watch video
Built with Qt - Lytro Light Field Imaging Platform
Built with Qt: Lytro is building the world’s most powerful Light Field imaging platform enabling art...
Watch video
Built with Qt: Meiller tipper truck app with KDAB
The app helps drivers diagnose and fix problems even when they are on the road or at a construction ...
Watch video
Built with Qt: Mercedes-Benz Generation EQ
The Mercedes-Benz Concept EQ is a one of the concept cars in generation EQ series, which are cars th...
Watch video
Built with Qt: Omnidome {On-demand webinar}
Watch the 'Built with Qt: Omnidome' demo showcased at SIGGRAPH 2020. You will learn: - How to map im...
Watch video
Built with Qt: OPW domain specific language overhaul with KDAB
OPW's domain-specific language (DSL) was too complex for the operating technicians. Every time a mea...
Watch video
Built with Qt: Parker Hannifin Application Designer
Together with The Qt Company, Parker Hannifin created a software development tool called Parker Appl...
Watch video
Managing the UX Platform Project, Parker Hannifin
Ville Nummela, Software Development Team Leader, managed a complex project including the development...
Watch video
Built with Qt: QIS revolutionizing cancer research with KDAB
Solving cancer is probably the biggest mystery that we will see unravel in our life. Because cancer ...
Watch video
Quantitative Imaging Systems and KDAB - Revolutionizing Cancer Research
Quantitative Imaging Systems (Qi) unravel cancer through digital imaging microscopy and machine lear...
Watch video
Built with Qt - Secure & Connected Carputer with LinkMotion
Qt Partner Link Motion has created a Carputer based on The Qt Automotive Suite. IVI & Cluster ru...
Watch video
Built with Qt: Symbio Elysian
Symbio - a digital services and R&D company - introduces Elysian, an infotainment solution that ...
Watch video
Tableau, Business Intelligence & Analytics Built with Qt
You guessed it – Tableau's responsive and stunning user interfaces are “Built with Qt”. The $3.5 Bil...
Watch video
Built with Qt - Wittenborg Coffee Machine
Qt Partner Witekio presents their company and their Wittenborg coffee machine demo.
Watch video
C++ to QML Animations {Qt Virtual Tech Con 2020}
Fluid UI Animations are the heart and soul of all modern User Interfaces. This webinar, aimed at Qt ...
Watch video
Certified Functional Safety with Qt Safe Renderer {On-demand webinar}
In this webinar we talk about functional safety and how the Qt Safe Renderer can be used in systems ...
Watch video
China Mobile Partners with Qt to offer graphical user interfaces on its IoT Operating System OneOS
China Mobile Partners with Qt to offer graphical user interfaces on its IoT Operating System OneOS I...
Watch video
Modern CMake for Qt Developers | Keynote | #QtWS21
With 55% of developers using CMake as a build tool for C++ code, CMake is the de facto standard buil...
Watch video
Coding with Qt for the Android Automotive Platform | Platform | #QtWS21
The presentation is about how Qt can be used for IVI development on the Android Automotive platform,...
Watch video
Community Driven QML Coding Guidelines - Autodesk {Qt Virtual Tech Con 2020}
The purpose of this talk is to introduce some of the guidelines that are already in place, and also ...
Watch video
Cost-effective embedded HMI solution {demo}
Create a fully digital experience for anyone Creating embedded technology with modern UIs can take t...
Watch video
Cost-Optimized HMI & Advanced GUI's for Automotive & Transportation Applications {On-demand webinar}
Join this webinar to learn how to leverage NXP i.MX RT1170’s powerful crossover MCU family and Qt cr...
Watch video
Python UI Builder: The Official Python Bindings for Qt
Everything you can do with C++ in Qt, you can do with Python instead! Creating UIs should be fast, f...
Watch video
Creating Advanced GUIs for Low power MCUs with Qt
Microcontrollers, often referred to as MCUs, are used in a growing array of systems and devices, inc...
Watch video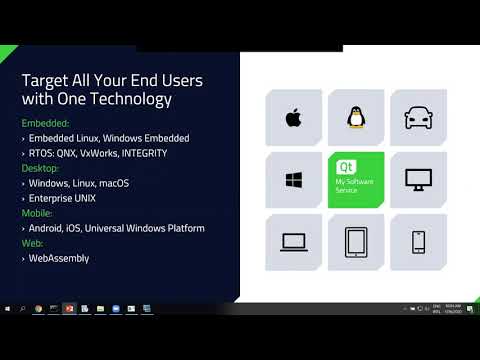
Creating Smart Devices with Qt on the NXP i.MX RT series
Ultimate Graphical Performance on NXP Microcontrollers with Qt for MCUs Get started with Qt for MCUs...
Watch video
Creating User Interfaces for Microcontrollers (Qt & NXP) - Part I
Qt for MCUs is a complete graphics framework and toolkit with everything you need to design, develop...
Watch video
Creating User Interfaces on MCUs {Qt Virtual Tech Con 2020}
Microcontrollers (MCUs) are ubiquitous in electronic appliances in consumer electronics, industrial ...
Watch video
Cross-Collaborative Qt GUI Testing: A Behavior-Driven Development Approach - Froglogic
Florian Turck, Technical Sales Engineer, Froglogic introduces the Squish GUI Tester as a test automa...
Watch video
Cross-platform software scalability explained
Qt Business Line Director Patrick Dalez explains the different dimensions of scalability and how Qt ...
Watch video
Customer Keynote: BSH Home Appliances GmbH | Keynote | #QtWS21
BSH Home Appliances GmbH is the leading manufacturer of household appliances in Europe with over 60,...
Watch video
Deliver a rich graphical UX without blowing your hardware costs - DevDes 2021
www.qt.io https://www.qt.io/product/qt6 Delivering a rich HMI within a limited budget often requires...
Watch video
Three advantages of Qt Quick 3D
Maurice talks us through a Qt Quick 3D demo shown at Embedded World 2022 that highlights three major...
Watch video
Design and Development communication to ensure a usable graphical interface
www.qt.io https://www.qt.io/product/qt6 While collaboration during development is helpful for code a...
Watch video
Design as a Team Sport - DevDes 2021
www.qt.io Every seasoned designer has fallen into the trap. They see the bad design in front of them...
Watch video
Designing delightful products
Powerhouse companies like Apple and Tesla are dependent on their UX. Learn why & how an excellen...
Watch video
Desktop Applications with Qt - Native Styling and the future
www.qt.io Join a Fireside-chat on Qt for Desktop, Qt Widgets, and Qt Quick for UIs that will rock yo...
Watch video
DevDes 2021: Digital Products Rewrite The Requirements For Development Tools
Watch a recording of Vice President and Principal Analyst Jeffrey Hammond's related keynote from the...
Watch video
Developing certified Medtech products with Qt {Qt Virtual Tech Con 2020}
During this session you will learn How Qt supports regulated medical product development: Best pract...
Watch video
Developing for Accessibility
www.qt.io It’s fairly easy to build powerful visual experiences using Qt Quick and QML. But what doe...
Watch video
Developing Modern Desktop Application in 2022 {On-demand webinar}
Desktop application development is rapidly evolving. To successfully develop modern software in 2022...
Watch video
Developing Qt6 Projects With CMake | Tools | #QtWS21
The Qt 6.2 release brings with it a smoother, simpler and more flexible CMake experience for develop...
Watch video
Digital Cockpit on Multiple Screens and Operating Systems
Built with Qt: Digital Cockpit on Multiple Screens and Operating Systems
Watch video
Digital Cockpit With Multi-OS Support
Three screens. Three operating systems. One exceptional user experience. #BuiltWithQt First shown at...
Watch video
Driving Down Development Costs for Richer HMIs with Qt & NXP i MX RT1170 {On demand webinar}
Automotive HMI solutions traditionally require complicated hardware and extensive architecture to ac...
Watch video
E-bike instrument cluster with low end System-on-Chip (SoC)
This is an e-bike instrument cluster concept designed and implemented in co-operation with Gofore. T...
Watch video
Embedded Machine Learning Based Decision Support for IoT | Platform | #QtWS21
Decision support systems require accurate decision support and intuitive interfaces to be accepted b...
Watch video
Embracing Python: From Prototypes to Hybrid Applications {Qt Virtual Tech Con 2020}
Qt for Python has been out officially more than one year, and during this period we have been gather...
Watch video
Empower your design of HMI/UX by integrating advanced simulation capabilities - Dev/Des 2021
In this talk, you will learn how your design of HMI/UX can benefit from early system-level simulatio...
Watch video
Enabling Next-Generation Drug Discovery
www.qt.io Pat Lorton, CTO at SchrĂśdinger, talks about the field of computational chemistry, and how...
Watch video
Enhancing Your UX to Engineering Workflow, ICS - DEVDES, 2021
Qt Design Studio promises to improve the User Experience (UX) to Engineering workflow by providing a...
Watch video
Ensuring GUIs Minimal Footprint & Maximal Performance in MCU Applications | User Interface | #QtWS21
Graphical user interfaces (GUIs) are increasingly present in MCU applications. Typical GUI implement...
Watch video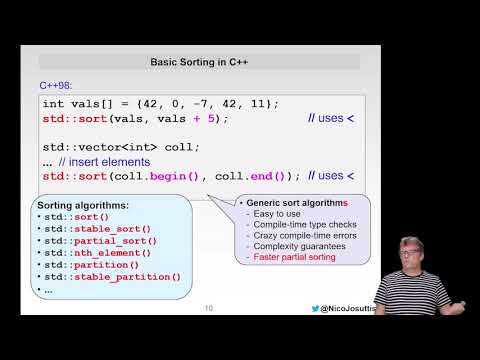
Even More Modern C++
Nicolai M. Josuttis Author of several C++ books, trainer, and member of the C++ standards committee ...
Watch video
Ford builds a virtual automotive feature simulator with Qt!
Ford has been using Qt to take the testing of new features inside their cars into the virtual space....
Watch video
Ford Motor Company Vehicle HMI - Building With Qt From the Very First Step
Ford's engineering teams use Qt right from the beginning of the vehicle HMI development process. Hig...
Watch video
Forrester study: Digital Products Rewrite The Requirements For Development Tools - dev/des 2021
https://www.qt.io/product/qt6 www.qt.io Digital products can improve customer experience, automate d...
Watch video
Foundation For the Future - Are we excited? {Qt Virtual Tech Con 2020}
Lars has been working on Qt for 20 years starting as a software engineer to later leading the global...
Watch video
Fresenius develops dialysis machines with Qt
Fresenius' dialysis machines are used all across the world to treat kidney diseases. Qt helps them c...
Watch video

Get Started creating dynamic UIs with Qt Design Studio and Photoshop on MCUs {On-demand webinar}
Watch the step-by-step walkthrough demo showcased at SIGGRAPH 2020 on Creating dynamic UIs with Qt D...
Watch video
Getting Started with QDS - Using the Qt Quick 3D Components
Get started with using Qt Design Studio. This video focuses on how to import and use the Qt Quick 3D...
Watch video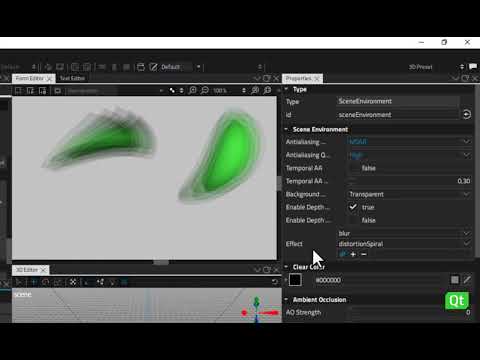
Getting Started with QDS - Using the Qt Quick 3D Custom Shader Utilities, Materials, and Effects
Get started with using Qt Design Studio. This video introduces the Qt Quick 3D Custom Shader Utiliti...
Watch video
Getting Started with Qt for Android {Qt Virtual Tech Con 2020}
In this webinar, we'll go through the steps for setting up the environment to work with Qt for Andro...
Watch video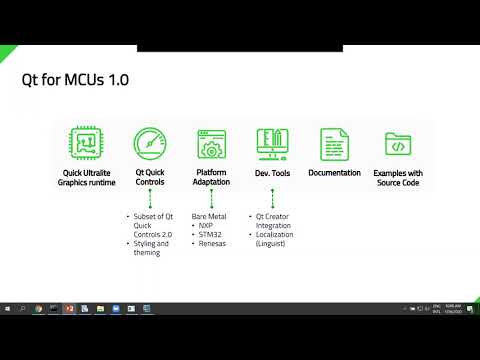
Getting started with Qt for MCUs 1.0 {on-demand webinar}
The recent launch of Qt for MCUs 1.0 – the new Qt Quick Ultralite rendering engine, running on bare ...
Watch video
Getting Started with Yocto & eLinux on Qt for Device Creation {Qt Virtual Tech Con 2020}
This is hands-on session will get you started with setting up and configuring Qt Creator on four dif...
Watch video
Girbau customer-focused design | Keynote | #QtWS21
Customer Experience in industrial and commercial environments is sometimes forsaken, but it makes th...
Watch video
Globus Medical: Imaging, Navigation, and Robotics with Qt | Graphics | #QtWS21
Computer-assisted surgeries are changing the nature of today’s operating room (OR). The technology i...
Watch video
Gofore Experiences the Qt-Enhanced UI Development Workflow
From Design to Deployment: Listen to Gofore's telling of how they prototyped for production with bla...
Watch video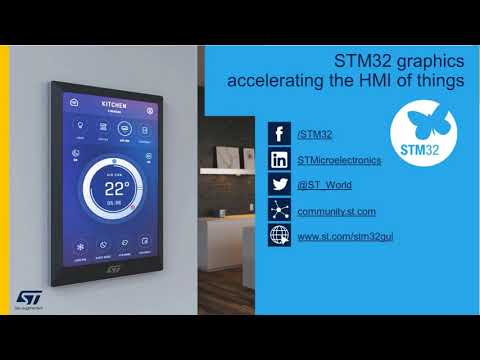
Graphics on STM32: tools for embedded GUI design and development {On-demand webinar}
Implementing a Graphical User Interface (GUI) for embedded devices is often more challenging than de...
Watch video
Harman Built 3D HMI System with Qt
Harman Built 3D HMI System with Qt Interview @ Qt World Summit 2021 China - Shanghai Meetup
Watch video
Hexagon's Product Line AICON builds 3D measuring systems with Qt
Try Qt now: https://www.qt.io/download Hexagon's Product Line AICON has developed, manufactured and ...
Watch video
How are Companies Overcoming the Global Chip Shortage {On-demand webinar}
61 % of decision makers agree that the current semiconductor shortage has negatively impacted their ...
Watch video
How designers and developers collaborate for Automotive HMI
Ciro discusses the steps required to take an automotive HMI from the first initial concepts all the ...
Watch video
How Mbition is modularizing the MBUX system for faster upgrades and greater resilience
In this keynote interview, Kai Uwe Broulik, Expert Software Engineer, Infotainment at MBition, the M...
Watch video
How NVIDIA Nsight Graphics Utilizes Qt to Create Powerful Tools for 3D Graphics | Graphics | #QtWS21
The ARM architecture is the most pervasive processor architecture in the world, so having the abilit...
Watch video
How Qt is equipping the industry with tools for the software-defined vehicle
The three key trends – electrification, automation, and connectivity – are reshaping customer expect...
Watch video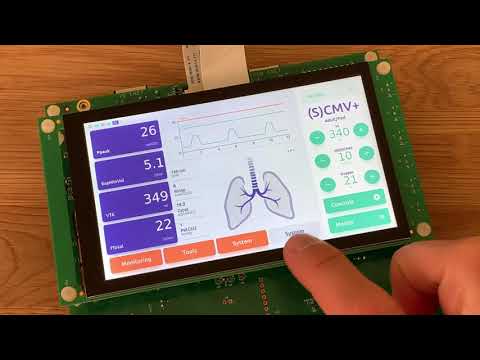
How to Create a Ventilator UI for MCUs overnight {Showcase}
Watch the full webinar for free:https://resources.qt.io/qt-mcus/how-to-create-a-medical-device-proof...
Watch video
How to foster collaboration between designers and developers - Roundtable at Embedded World 2021
Break the cycle of painstaking feedback loops between designers and developers. Use unified design a...
Watch video
How to improve the UX of an industrial robot with Qt - DevDes 2021
www.qt.io Programming a robot arm is a challenge since there are a lot of menus and submenus, no int...
Watch video
How to painlessly migrate from MFC to Qt
Microsoft Foundation Class Library (MFC) is a legacy C++ object-oriented library on Windows that exi...
Watch video
How to Turn Your Design Visions into Functional Products {On-demand webinar}
When creating a working UI, there is often a disconnect between the designer’s vision and what devel...
Watch video
How your Python projects can benefit from Qt? {On-demand webinar}
- How Qt plays in the Python world & the latest and greatest from Qt 6.3: Discover the insights ...
Watch video
HTML5 vs Qt {showcase}
One man, three weeks to create an application using HTML5 and three weeks using Qt. The result speak...
Watch video
Hybrid Qt Development: Boosting Your Projects with Python | Platform | #QtWS21
Qt has been under development for many years, and it has been evolving with the community and the de...
Watch video
Hybrid UI in Tableau Desktop
www.qt.io Tableau Desktop uses communication between web UI and native code to build new features an...
Watch video
i.MX RT1170 Crossover MCUs - Ushering in the GHz Era of MCUs
Join this session for an overview of the 1GHZ i.MX RT1170 MCU family to support your consumer, indus...
Watch video
Improve Time to Market for Industrial Edge Devices {On-demand webinar}
Qt and WINSYSTEMS have collaborated to provide an out of box experience on industrial-grade embedded...
Watch video
In-Depth Model/View with QML - ICS {Qt Virtual Tech Con 2020}
The model/view design pattern is the standard way of separating UI from business logic, especially w...
Watch video
Interview with Jim Tieman (Neocis) | Keynote | #QtWS21
Neocis is developing a dental surgery robot and is utilizing Qt to build the key functionalities on ...
Watch video
Introducing Qt 3D Studio
NVIDIA made one of the largest contributions ever to Qt. They contributed the entire NVIDIA DRIVE™ D...
Watch video
Introducing Qt 5.9 - Release video
High performance & stable new features. It’s even long term supported. From 5.7 and onwards Qt i...
Watch video
Introducing Qt for MCUs. Ultimate performance. Tiny footprint.
More about Qt for MCUs here: https://www.qt.io/qt-for-mcus Qt for MCUs 1.0 is finally available for ...
Watch video
Introduction to Functional Safety & Security, LDRA, {Qt Virtual Tech Con 2020}
There is increasing demand for QT based GUI driven applications in the safety critical sectors, wher...
Watch video
Introduction to Qt Creator IDE {Qt Virtual Tech Con 2020}
Qt Creator is a powerful IDE aimed at making you a more productive C++ and Qt programmer. This webin...
Watch video
IoT Revolution: Introducing connected coffee machines built with Qt {On-demand webinar}
Most of our consumer appliances and for example coffee machines are being connected online. IoT allo...
Watch video
IoT Today and Tomorrow - Qt Demo
Qt Internet of Things Sensor Demo built with Texas Instruments Sensortag.
Watch video
Kickstart your Qt Project on NXP i.MX 8 Series Application Processors {On-demand webinar}
The latest NXP i.MX 8 Series of applications processors provide a very reliable computing platform w...
Watch video
Level up your Business Intelligence for the next generation coffee machine
As the number of connected devices is projected to reach 75.44 billion worldwide by 2025, consumer p...
Watch video
LG Electronics use Qt to power their evolving webOS platform
LG Electronics is expanding their 'built-with-Qt', webOS platform into the automotive space with web...
Watch video
Low-End Digital Automotive Instrument Cluster {showcase}
In volume products, it's all about reducing the bill of materials (BOM) cost and squeezing the juice...
Watch video
Lufthansa Technik takes Qt into the skies - Built with Qt and KDAB
For VIP and business aircrafts, »nice« is the industry standard in cabin management and in-flight en...
Watch video
Machine Learning meets Embedded Development {On-demand webinar}
Qt and Ekkono are working together to improve machine learning integration in the embedded developme...
Watch video
Making music: Architecting realtime audio development with QML - DevDes 2021
www.qt.io At Vochlea, they have built vocal-controlled music-making software that employs real-time ...
Watch video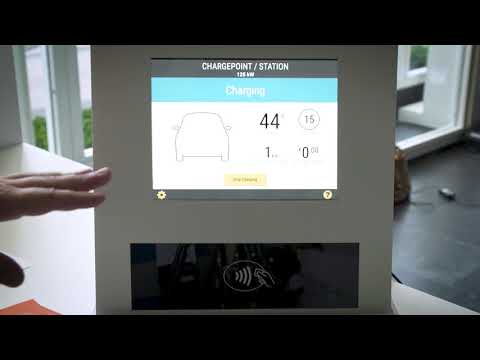


Medical demo created with Qt Design Studio running Qt Safe Renderer on Integrity RTOS {showcase}
Roger Mazzella from The Qt Company shows off our latest infusion pump demo. It was created with Qt D...
Watch video
Meet Qt 6.2 LTS - Ask us anything! {On-demand webinar}
With such an epic release as Qt 6.2 LTS – the first long-term supported version of Qt 6 – , we are r...
Watch video
Meet Qt 6 - DevDes2021
Join Qt speakers as we introduce Qt 6, the latest version of Qt, and the cross-platform software dev...
Watch video
Meet Qt 6 {On-demand webinar}
Join Lars Knoll and Tuukka Turunen to learn about the all-new Qt 6 with Q&As. Qt 6 offers you Th...
Watch video
Meet Qt Nordics Online 2020
Join us in a complimentary online Meet Qt Nordics seminar with live Q&A to learn how to create b...
Watch video
Meet Qt Spain Online
Watch online Meet Qt Spain seminar with Q&A to learn how to create better connected devices, UIs...
Watch video
Migrate to Qt 6.2: Solid performance. Stability. Long-term Support | Platform | #QtWS21
Qt 6.2 is the first long-term supported (LTS) version in the Qt 6 series and is thus the next go-to ...
Watch video
Minimizing Risks When Building an Instrument Cluster HMI {On-demand webinar}
" Realizing your UX vision for an instrument cluster is often not straight forward and easy. Since d...
Watch video
Modern Application Development for Any Domain {On-demand webinar}
With the rise of the high-resolution, responsive mobile user interface has come rising user expectat...
Watch video
Modern microcontroller (MCU) application development with Qt {On-demand webinar}
Qt for MCUs is a complete graphics framework and toolkit with everything you need to design, develop...
Watch video
Modern Qt Development with Software Containers for Devices
www.qt.io Software Containerization is all the rage. Toradex' Stefan Eichenberger talks about the ad...
Watch video
Monetization 101 for Connected Devices {On-demand webinar}
Now you can generate revenue from any embedded screen with the new Qt Digital Advertising Platform. ...
Watch video
Moving to Vulkan in Qt for Automotive - Pros & Cons, Siili {Qt Virtual Tech Con 2020}
Join Filip in a live webinar on Vulkan with Qt in the Automotive context. The talk will cover follow...
Watch video
Multimodal User Interfaces on iMX RT Crossover MCUs, NXP - DEVDES 2021
Embedded user interfaces (UI) increasingly combine aspects of graphics, audio, and voice into one co...
Watch video
Next Generation Industrial UIUX in a Post Pandemic World - DevDes2021
www.qt.io The adoption of capacitive touch sensing technology is expanding rapidly. The spread of CO...
Watch video
Next-Generation Smart Home Designs with High-Performance Qt for MCUs | User Interface | #QtWS21
Next-generation smart home devices are increasingly interactive, intelligent, and personalized. Join...
Watch video
Next Level User Experience for Medical Devices {On-demand webinar}
Medical industry is in a need of modernizing a lot of products while also bearing in mind the safety...
Watch video
Not your Grandmother's Embedded Systems
www.qt.io In his talk, Clive ‘Max’ Maxfield will cover the past and future of embedded development, ...
Watch video

{On-demand webinar} Digital Ads 102 - Your Screen Is A Cash Register
Did you know that wherever there's a digital screen connected to the internet, there's potential for...
Watch video
{On-demand webinar} WebAssembly: The Next-Generation Web Platform
WebAssembly is a bytecode representation that is meant to be targeted by high-level programming lang...
Watch video
One framework to rule them all - Introducing Qt 5.8
Qt just got even more awesome -- We are always working on improving Qt to ensure it continues to be ...
Watch video
One team, One dream - Seamless User Experience Design for Multiple Device Families
Emmanuel Penzes, Pre-sales Engineer, The Qt Company, shows you how to deploy the same software to mu...
Watch video
Scaling Digital Cockpit Development
The in-vehicle digital experience often falls short of user expectations, with drivers choosing inst...
Watch video
Oven UI/UX Design with the Qt toolchain - Dev/Des 2021
www.qt.io https://www.qt.io/product/qt6 The complexity and level of graphical details for home appli...
Watch video
PDF rendering in Qt Quick {Qt Virtual Tech Con 2020}
Qt has recently added a more full-featured wrapper around PDFium, the same implementation that Chrom...
Watch video
Set Yourself up for Success - Lessons Learned from Building 100+ Devices with C++/Qt/QML
These days everything depends on software, and that software is growing more and more complex. It’s ...
Watch video
Product differentiation through your ebike HMI
As major cities move to adopt to a new post-pandemic reality, electric Bikes are going to leap forwa...
Watch video
Training: Programming for Microcontrollers (STMicroelectronics)
Qt for MCUs is a complete graphics framework and toolkit with everything you need to design, develop...
Watch video
Programming Smart devices with Qt for STM32 family {On-demand webinar}
Ultimate Performance. Tiny Footprint. Create Graphical Applications with on STM32 Cortex M7 processo...
Watch video
Prototyping for Production: Watch your designs come alive on your device {showcase}
This is a teaser of what we are currently working on with our designer offering. Visit our web page ...
Watch video
Python and C++ interoperability with Shiboken {On-demand webinar}
C++ and Python are two fantastic programming languages that bring to the table a considerable amount...
Watch video
Python and C++: the best of both worlds
www.qt.io Dr. CristiĂ n Maureira-Fredes, R&D Manager at The Qt Company of PySide fame dives into...
Watch video
QML/C++ Architecture Best Practices & QML Tips for Efficient Development - Dev/Des 2021
This talk targets all engineers who want to improve their QML knowledge. In this talk, you learn: * ...
Watch video
QML for building beautiful desktop apps - Dev/Des 2021
QML is already among the best tools for building beautiful applications for touch screen devices. Bu...
Watch video
Qt 3D Studio Home Automation Demo
Watch how you can create graphical elements in your favorite design tool, import them in Qt and use ...
Watch video
Qt 3D Studio release introduction
Watch the highlights of the Qt 3D Studio, a world class 3D User Interface design tool that supports ...
Watch video
Qt 5.15 LTS: Built to Last
Qt 5.15 LTS will be the last momentous release before the great transition into Qt 6. We have gone t...
Watch video
Qt 5.9 on INTEGRITY RTOS
The Green Hills INTEGRITY Real-Time Operating System (RTOS) is widely used in safety- and security-c...
Watch video
Qt 6.2 and beyond | Keynote | #QtWS21
On the keynote presentation, the Qt Company's CEO Juha Varelius, Chief Architect Lars Knoll, and VP ...
Watch video
Qt 6.2 LTS vs. Qt 5.15: The big feature parity comparison {On-demand webinar}
We have built Qt 6 as the Productivity Platform for the Future to empower Next-Generation 3D/2D User...
Watch video
Qt 6 on the desktop. Ready for the next decade
www.qt.io Qt has been evolving for more than 25 years now and with Qt 6 took the next major step. Fl...
Watch video
Qt and OpenAPI/Swagger - a tutorial - Dev/Des 2021
OpenAPI (aka. Swagger) is a widely used technology to implement APIs in a cloud/IT context. It provi...
Watch video
Qt and Software Containers for Embedded Devices
www.qt.io Software Containerization is where it’s at! Would you agree? Learn about the advantages an...
Watch video
Qt at ARM TechCon by Toradex - Built with Qt
1. Self-Balancing TAQ Robot runs two separate operating systems with the same hardware and use them ...
Watch video
Qt brings Ulstein's daring & industry disruptive vision to reality
The first project with Qt and The Qt Company services team, has enabled Ulstein Power & Control ...
Watch video
Qt CoAP - leveraging C++ and Qt for cross-platform IoT apps {On-demand webinar}
Introducing Qt CoAP - leveraging C++ and Qt for cross-platform IoT apps CoAP is a specialized web tr...
Watch video
Qt Core UI, Live Forum {On demand webinar}
Let's talk Qt Application Architecture! Creating a user experience that is simple for the user, spec...
Watch video
Qt Creator in Space | Tools | #QtWS21
In this talk, you will learn good practices in creating Qt Creator plugins and hear experiences on h...
Watch video
Qt Debugging & Profiling
Qt Debugging & Profiling – The developer experience with productivity at its core. From developm...
Watch video
Qt demo: Cross-platform smart oven app
Qt Senior Pre-Sales Engineer Stefan Jost walks you through the home appliance demo, which showcases ...
Watch video
Qt Design Studio for Great Designs and Collaboration
Working relationships between designers and developers can be complicated. It's as if they speak dif...
Watch video
Qt Design Studio & Software Development Integration {On-demand webinar}
When creating a working UI (user interface), there is often a disconnect between the Designer’s UI d...
Watch video
Qt design workflow explained
Qt Technical Artist Arnaud Armengaud explains step-by-step how designers can create production-ready...
Watch video
Qt Embedded Days - Creating Automated GUI Tests for Embedded Applications by Tomasz Pawlowski
There’s an ever increasing amount of computing power available in embedded devices. With technology ...
Watch video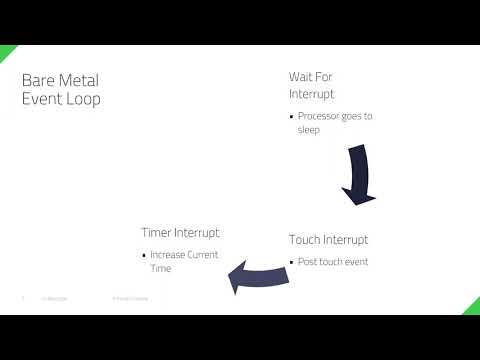
Qt for MCUs Deep Dive {Qt Virtual Tech Con 2020}
Qt for MCUs is a new offering where we combine Qt’s delightful declarative approach to user interfac...
Watch video
Qt for MCUs Demo: Fitness Console (Treadmill)
Check out this treadmill console demo, with animated backgrounds and smooth animations, 'running' on...
Watch video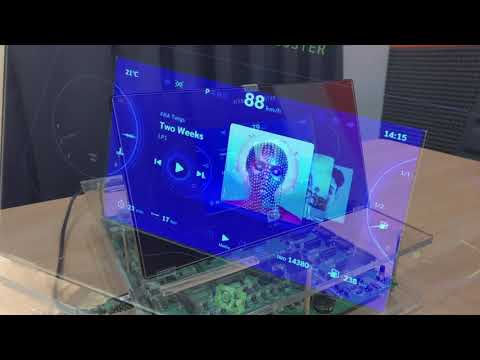
Qt for MCUs: Hybrid Instrument Cluster on a Renesas RH850-D1M1A Microcontroller {showcase}
Qt for MCUs 1.1 offers a complete graphics framework and toolkit with everything you need to design,...
Watch video
Qt for MCUs - Installation Guide
Join Qt's Devinder Sodhi as he guides you step by step through the installation process for Qt for M...
Watch video
Qt for MCUs | Low-Cost Advanced HMI & GUIs on Infineon Traveo II {Showcase}
Qt and the new Infineon's HMI Tool Certification Program help users build rich, scalable, and next-g...
Watch video
Qt for MCUs: Motorcycle Instrument Cluster on a NXP i.MX RT1170 EVK microcontroller {showcase}
Qt for MCUs 1.1 offers a complete graphics framework and toolkit with everything you need to design,...
Watch video
Qt for MCUs: Motorcycle Instrument Cluster on Renesas RH850 microcontroller {showcase}
Qt for MCUs 1.1 offers a complete graphics framework and toolkit with everything you need to design,...
Watch video

Qt for MCUs - Wearable smartwatch demo by Siili Auto - NXP Microcontroller
A smartwatch demo showing a fitness wearable UI with a full feature set from clock, to monitoring wo...
Watch video
Qt for Python: Introduction to the Shiboken Wizard
Starting from 6.1, commercial users will be able to use the Technical Preview of the new tool: Shibo...
Watch video
Qt for Python: Repository overview
Would you like to discover what is inside the main repository of the project? Are you curious to kno...
Watch video
Qt for Python: Resources overview
Do you know the wiki, website, and repository locations? if it feels like too many resources, this v...
Watch video
Qt for WebAssembly {showcase}
Qt for WebAssembly lets you build Qt applications for web browsers. Code once, deploy everywhere - e...
Watch video
Qt Hackathon Compilation
Check out what impressive feats of graphic performance our talented devs cobbled together in just tw...
Watch video
ICS builds Alexa Voice-Controlled Systems with Qt
ICS VP of Engineering Roland Krause talks voice-controlled infotainment systems and how he used Qt t...
Watch video

Qt Installer Framework with Qt 6 | Tools | #QtWS21
In this talk we will explore functions that assist developers in both packaging and deploying their ...
Watch video
Qt is everywhere! Watch the video!
Qt is everywhere! Explore all the expected and unexpected places where Qt touches our lives!
Watch video
The World's Fastest Electric Supercar, Qt IVI & Cluster in Rimac's Concept One
The World's Fastest Electric Supercar deserves The World's Fastest Software and that's why they chos...
Watch video
Qt Configuration Tool - Reduce Your Footprint & Optimize Performance
Qt for any platform, any thing, any size Reduce your footprint by up to 60% and optimize performance...
Watch video

Qt Lottie: Embedding Adobe After Effects right in your application
Thanks to the Qt Lottie library, UX designers can now embed their designs into applications directly...
Watch video
Qt for MCUs - Thermostat demo on STM32F769I-Disco
Qt for MCUs. Ultimate performance. Tiny footprint. Create fluid UIs with a low memory footprint on m...
Watch video
Message Queuing Telemetry Transport, Qt MQTT Demo
Publisher-subscriber protocols have become more and more attractive to automation infrastructures. M...
Watch video
Qt MQTT IoT connectivity for different OS and HW {showcase}
In this video, Maurice shows how Qt MQTT enables IoT connectivity on different operating systems and...
Watch video
Qt or Android: Let's compare!, Witekio {Qt Virtual Tech Con 2020}
Android and Linux-Qt are both a popular choice to develop graphical UIs on embedded devices. But hav...
Watch video
Welcome to Outrun - Teaser
Welcome to Outrun - an automotive demo built by Qt If you want to know more about this project, plea...
Watch video
Qt Partner basysKom's OEM Custom Configurator #BuiltwithQt
Live Embedded World demo with Qt running on Windows and Embedded Linux using Qt Charts, Sensors and ...
Watch video
Qt Productivity Tips - Highlights from Qt Widgets and More | Tools | #QtWS21
For more than a year Jesper Pedersen has hosted a Youtube series focusing on Qt Widgets and everythi...
Watch video
Qt Professional Services
Our teams are specialized to advise, design, support and implement your solutions. We build Proofs o...
Watch video
Qt Quick 3D Benchmark Demo
A clip from the brand-new benchmark application for Qt Quick 3D.
Watch video

Qt Quick 3D Introduction & Best Practices {Qt Virtual Tech Con 2020}
Qt Quick now makes it easier than ever to incorporate 3D content into your application or HMI via th...
Watch video
Qt Quick 3D Particles, Mesh Morphing and Instancing Using Qt Design Studio | Graphics | #QtWS21
Join Jarko to discover how you can add advanced 3D features directly from Qt Design Studio. Continui...
Watch video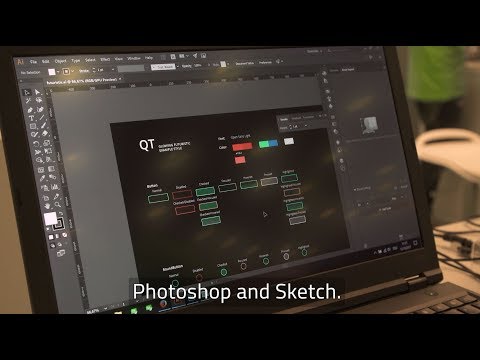
Branding All of Your Controls with Qt Quick Controls Imagine Style
From Qt 5.10, Qt Quick Designer allows you to style or skin the UI Forms (ui.qml files) of the Qt Qu...
Watch video
Qt Quick Software Renderer on i.MX6 ULL by KDAB {showcase}
KDAB's Kevin Funk demos how Qt applications run on low-end hardware with fluid 60fps without GPU acc...
Watch video
Qt Quick WebGL demo: camera remote control
Qt Quick WebGL demo. Qt-based application running on Raspberry Pi, controlling the camera’s pan and ...
Watch video
Functional Safety, Safeguarding Users with Qt Safe Renderer
With Qt Safe Renderer you are able to separate the functional safety critical parts of your software...
Watch video
Qt Safe Renderer and Top 5 Questions, Live Forum {On-demand webinar}
Get in the know! Learn more about Qt Safe Renderer; where does the Qt Safe Renderer fit in, and what...
Watch video
Qt SCXML and state machine tooling in Qt Creator
This video demonstrates the usage of the Qt SCXML module and how Qt Creator supports us when using t...
Watch video
Qt Showcase KNX Automated Home {Showcase}
Maurice Kalinowski shows a complete building automation demo based on Qt and KNX. Check out more coo...
Watch video
Qt Showcase MTA Multidisplay
MTA offers a complete “In-Vehicle” system with fast dynamics, very high-performance processors, and ...
Watch video
Qt Smart Oven with Renesas RZ/G Linux Platform {showcase}
Create leading edge user experiences with smart hardware/software collaboration. Key Features: - Emb...
Watch video
Autodesk Builds Infrastructure Design with Qt
Christine Lehmann and Sebastian Voigt, developers for Autodesk Infraworks, talk about their experien...
Watch video
CEWE's Photoworld Builds Lasting Memories with Qt
If your German's a bit rusty, you can enable English subtitles. Software developer Daniel MĂźller ta...
Watch video
Mercedes-Benz' MBUX is Built with Qt
Head of UI/UX development at Mbition, Mykhaylo Chayka, talks about the user experience behind Merced...
Watch video
Omron Builds Machines to make better people -- Built with Qt
The HMIs in Omron's machine are designed to help people be better at their job. Michel Min talks abo...
Watch video
LG: Building webOS with Qt
LG's webOS, made famous with their wonderful smart TVs, has become a staple in modern consumer elect...
Watch video
Qt vs. JavaFX by Sequality {Showcase}
Stefan Larndorfer with Sequality conducts a head-to-head comparison of the same application running ...
Watch video
Qt WebEngine {Qt Virtual Tech Con 2020}
The chromium-based web rendering solution has been helping many products to succeed when there was a...
Watch video
Qt WebGL Streaming Demo
Our Qt Advisor Michael Winkelmann shows a WebGL streaming demo developed for the project DruckMessWT...
Watch video

Yuneec Unleashes the Drones with Qt
Global Software Director Paul Chen talks about how Yuneec stays lean and maintains its code base wit...
Watch video
Qt6 and other cool new stuff - What's cooking? (part 2)
www.qt.io This is part 2 of Lars Knoll's Qt World Summit Online keynote on all the great and new in ...
Watch video
Qt6 and other cool new stuff - What's coooking? (part 1)
www.qt.io Join Lars Knoll on a life-changing journey of discovery through the all-new Qt 6. Lars tal...
Watch video
QtKNX Demo with Andrew O'Doherty
This demo shows implementation of M2M protocol standard in building automation application, interact...
Watch video
Qt's super-safe medical device demo
Qt Pre-sales manager Amit Nainawat showcases a medical device demo at Embedded World 2022. The demo ...
Watch video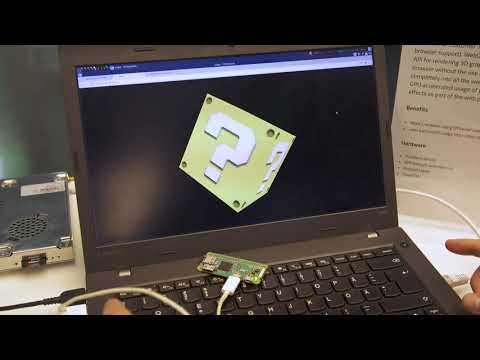
QtWebGL Demo - Remote control and streaming
With an increasing number of connected devices arising, grows a need for domain-specialized services...
Watch video
Quby builds energy-saving smart thermostats with Qt
A thermostat that helps you save energy? Quby's Toon does just that. And just as this little rascal ...
Watch video
Building Qt for Any Embedded Technology
Rami Potinkara, Sr. Manager in Qt R&D will talk about a cookbook and practical tools to boot dev...
Watch video
Rapid UX prototyping to test and communicate UX {On-demand webinar}
Adopting methods for rapid UX prototyping and including developers in iterative user testing ensures...
Watch video
Built with Qt - Raytheon AnschĂźtz loves QML - with Jakob Gaude
Jakob Gaude with Raytheon AnschĂźtz explains how they could speed up development and prototyping wit...
Watch video
Real-time 3D made easy with Qt Design Studio and Qt Quick 3D
Imbue your designs with HDR lighting, physically-based PBR materials, custom animations/transitions,...
Watch video
Roadmap to the Future of Qt {On-demand webinar}
What lies ahead and how are we building the cross-platform tool of the future for you? How are the k...
Watch video
Rust binding for Qt : How to mix QML with Rust
Rust is a modern system programming language that emphases on performance reliability and productivi...
Watch video
Saab Technologies uses Qt for aerial and marine traffic management
Want to try Qt yourself? Head over here: https://www.qt.io/download Saab Technologies tracks the tra...
Watch video

Shaders and Materials for 2D/3D Contents in Qt 6 | Graphics | #QtWS21
Qt 6 introduces a new layer for managing 3D APIs, such as, Vulkan, Metal, Direct 3D, and OpenGL, tog...
Watch video
Siili Solutions design and develop faster with Qt, Built with Qt Keynote @QtWS18
For additional customer story videos and other content, take a look at our resource center: https://...
Watch video
SilhouetteFX: Award-Winning Visual Effects Software - Built with Qt
SilhouetteFX is a 2 x Academy Award Winning rotoscoping and paint visual effects software built with...
Watch video
SSL/TLS in Qt: Introduction to wolfSSL - wolfSSL {Qt Virtual Tech Con 2020}
Qt has traditionally used OpenSSL as the provider for SSL/TLS in Qt Network for secure network commu...
Watch video
STM32 Accelerating the HMI of Things with Qt & TouchGFX {On-demand webinar}
Devices featuring connected and smartphone-like user experiences are quickly becoming an industry st...
Watch video
Stunning Wearable Design & MCU Development Trends {On-demand webinar}
Wearable technology are electronic devices that are most popular worn as accessories; however, other...
Watch video
Styling a Qt Quick Controls Desktop Application | User Interface | #QtWS21
Qt Quick Controls comes with a powerful styling API that lets you polish your application to make it...
Watch video
Styling Qt Quick Controls 2 with Photoshop
We are researching a new approach on how to style Qt Quick Controls 2 from Photoshop or other design...
Watch video
Using less code to do more things with Qt, System SPA, Federico Di Mattia
Multiplatform capabilities, powerful libraries and more time to do more things are some of the reaso...
Watch video
The best chance at success for your embedded products - DevDes 2021
Although the title is a reference from soccer, embedded design is another area where it’s extremely ...
Watch video
The Evolution of the LGPL License Agreement -- A Review of the LGPL v3 {Qt Virtual Tech Con 2020}
In this webinar, attendees will learn how to comply with the requirements of the GPL/LGPL v3 License...
Watch video
The Future of QML {Qt Virtual Tech Con 2020}
The QML language and engine will face major new challenges and developments in Qt 6. In order to sca...
Watch video
The New Property Bindings: Making C++ more QMLish | Platform | #QtWS21
With the introduction of QML, it was possible to do reactive programming in Qt by creating bindings....
Watch video
The new Qt Multimedia in Qt 6.2
The multimedia support in Qt has seen some larger changes between 5.15 and 6.2. Those were triggered...
Watch video
The Possibility of Where
www.qt.io 'See What Others Can't' through Esri's powerful geographic information system (GIS) and th...
Watch video
The QmlBook - Learning by Reading | User Interface | #QtWS21
The QmlBook is an online resource for learning Qt and QML. It focuses heavily on the QML side of thi...
Watch video
The State and Future Directions of the Qt Graphics Stack {On-demand webinar}
The way Qt handles accelerated 2D and 3D graphics is facing its biggest changes since Qt 5.0. Relyin...
Watch video
Toradex Barcode Scanner Built with Qt {Showcase}
This 1D or 2D barcode scanner runs on on Android with Qt. It's like shopping for fruit with a Star T...
Watch video
Total War Editors & Qt | Keynote | #QtWS21
Total War is a multi-award-winning AAA games franchise, developed by Creative Assembly, powered by a...
Watch video
Transport & Logistics Qt application using Blockchain and MQTT {Showcase}
This demo shows how MQTT enables communication throughout the supply chain. The Qt UI enables a live...
Watch video
Tunneled 4K HDR video support for Qt/QML on Android | Keynote | #QtWS21
Currently, Qt Multimedia renders video to a SurfaceTexture which requires the Android framework to a...
Watch video
Turn your product into a revenue machine with Qt Digital Advertising Platform {On-demand webinar}
Qt Digital Advertising enables you to create a new revenue stream for your product by serving ads to...
Watch video
Turning the automotive HMI trends into reality - Industry Round-table
In this industry round-table our expert panelists discuss automotive HMI trends like over-the-air up...
Watch video
Ubuntu - The #1 Linux Distro is Built with Qt
The #1 Linux distro is more popular than ever — and on an even wider range of applications than you ...
Watch video
Ulstein disrupts the automation industry with daring vision - Part II
The first project with Qt and The Qt Company services team, has enabled Ulstein Power & Control ...
Watch video
Ultimate Scalability with Qt - Dev/Des 2021
www.qt.io https://www.qt.io/product/qt6 Scalable solutions - the holy grail for each product creatio...
Watch video


Variable Fonts: Creating a better in-car UX for consumers, Monotype {Qt Virtual Tech Con 2020}
Tom Rickner is a Creative Type Director with a career in type that spans more than three decades. Du...
Watch video
Verolt's HomeChef Qt app connects web, embedded (MCU), and mobile {showcase}
Verolt Engineering created its HomeChef app for four different platforms: mobile, embedded, and web....
Watch video
Virtual reality cockpit built with Qt Design Studio and Autodesk VRED
Try Qt Design Studio: https://www.qt.io/design Brook shows you a cool demo of an instrument cluster ...
Watch video
Virtual Reality with Qt Quick 3D | Graphics | #QtWS21
Rendering for virtual reality can prove challenging as not doing it correctly can make users feel il...
Watch video
Welcome Meet Qt {Qt Virtual Tech Con 2020}
Marko Finnig, Product Director at the Qt Company kicks off the 2020 Virtual Tech Con with an introdu...
Watch video
Welcome to Outrun - Behind the scenes
Welcome to behind the scenes of Outrun – the multi-screen digital cockpit demo for automotive built ...
Watch video
Welcome to Outrun - The full digital cockpit
Welcome to Outrun – an automotive UI demo showcasing the possibilities of building a multi-screen di...
Watch video

What Does it Take to Add Data Encryption to a Qt Application? | Platform | #QtWS21
The current legislation in Europe together with the rise of cybercrime makes holding unencrypted pri...
Watch video
What is Qt Design Studio? Explained by a Designer
Qt's Senior Technical Artist Arnaud Armengaud talks about the all-in-one UI design and prototyping t...
Watch video
What is Qt Digital Advertising and why it's awesome!
Nail Valiyev talks us through the capabilities of the Qt Digital Advertising based on different demo...
Watch video
What is Qt for MCUs
Qt for MCUs is a complete graphics framework and toolkit with everything you need to design, develop...
Watch video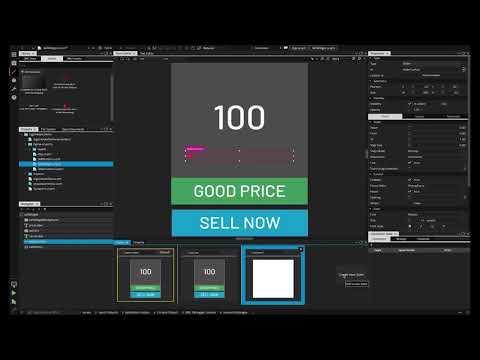

Where HMIs are going and how to develop them
The automotive industry is facing significant changes in technology, business models, supplier relat...
Watch video
Why software is the new product differentiator - Dev/Des 2021
www.qt.io As companies move to the new post-pandemic reality, consumer demand for better and faster ...
Watch video
Why to build your next IVI system with Qt and Android Automotive OS - Dev/Des 2021
Android Automotive is a new challenger in the infotainment segment. It brings a lot of benefits, mai...
Watch video
Witekio's Touchscreen Coffee Machine UI Built with Qt Quick {showcase}
The French know their coffee. Turns out the lads at Witekio also know their Qt development. Check ou...
Watch video
Yanfeng Visteon Built MCU HMI Development Platform with Qt
Yanfeng Visteon Built MCU HMI Development Platform with Qt Interview @ Qt World Summit 2021 China - ...
Watch video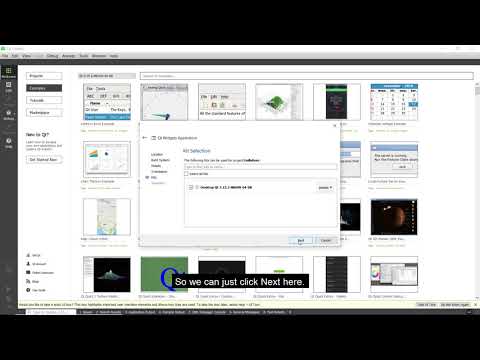
Creating a simple widget app
In this video, we'll show you how to create a simple widget-based application and run it on your dev...
Watch video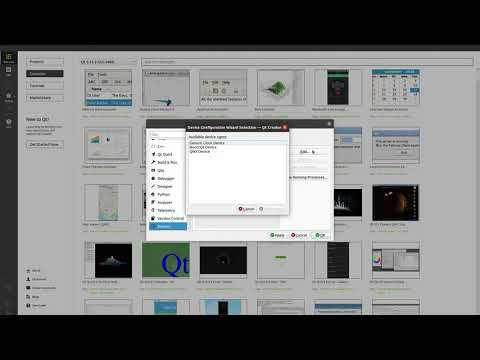
How to set up and deploy an application using Qt for Device Creation
In this video, we'll show you how to setup and deploy an example application for your device using Q...
Watch video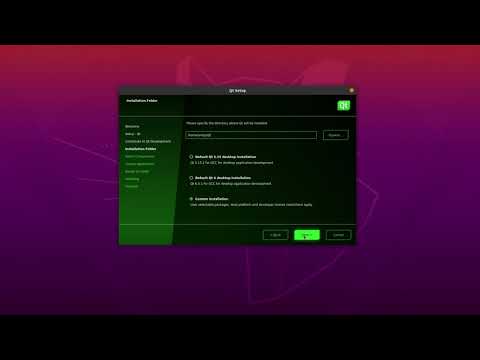
How to install and set up Qt for Device Creation on Linux
In this video, we'll show you how to download and install Qt for Device Creation with the options th...
Watch video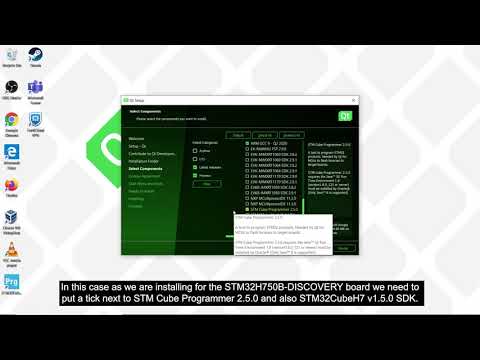
How to install and set up Qt for MCUs
In this video, we will show you how to download and install Qt for MCUs with the options that you wa...
Watch video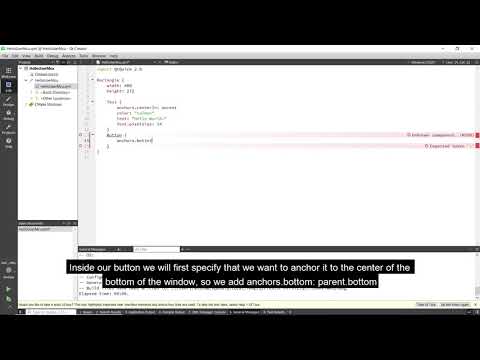
How to create a simple application with Qt for MCUs
In this video we will show you how to create a simple Qt for MCUs based application and run it on yo...
Watch video
Qt Widgets or Qt Quick
In this video, we'll explain the differences between Qt Widgets and Qt Quick and how to make the rig...
Watch video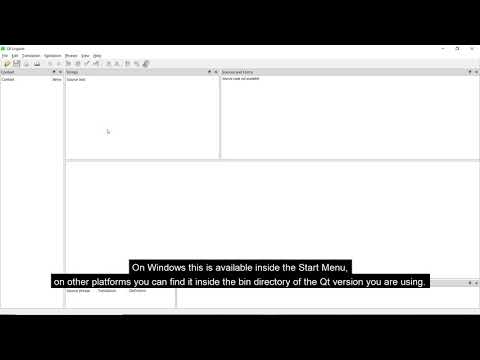
How to do translations with Qt Linguist
In this video, I will be showing you how to set up your Qt application ready for translation with th...
Watch video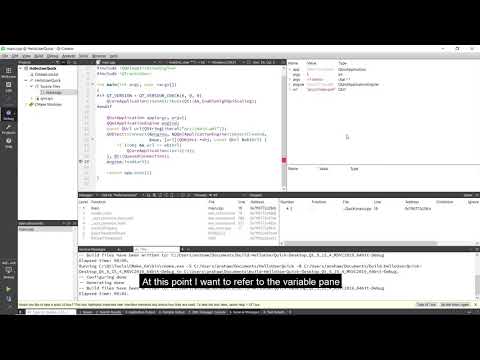
Debugging inside Qt Creator
In this video, we'll show you how to debug your application inside Qt Creator using the tools availa...
Watch video
Qt Quick 3D: An Introduction and Best Practices
Andy Nichols shows us what Qt Quick 3D is, what you can do with it, and what it is best at – live in...
Watch video
Getting Started with Qt {Qt Virtual Tech Con 2020}
Get started with Qt and its IDE, Qt Creator, and join our webinar where Qt’s Pre-sales Engineer will...
Watch video
Using Qt to Support Both MCU and MPU in Your Application {On-demand webinar}
When your customers want to enjoy their favorite software on multiple devices, they expect a consist...
Watch video
Turning Your Digital Screens into Cash Registers | #QtWS22
This talk will walk you through what it takes to turn your digital screens into another Cash Registe...
Watch video
Calculating the ROI of Qt Software is not Rocket Science | #QtWS22
Customers and prospects sometimes wonder how to illustrate the financial value of Qt to decision-mak...
Watch video
How to Know When it’s Time to Call in an Expert | #QtWS22
Software development projects are increasingly complex. Successful projects require skilled staff wi...
Watch video
Transforming Your Business With Qt | #QtWS22
When you think of Qt, what is the first thing that comes to mind? Great product? Cross-platform capa...
Watch video
Qt Insight. Learn Your Customers. Optimize the Experience | #QtWS22
We believe that to truly understand your customers, you need to learn from them. Learn how, when, an...
Watch video
Qt & QNX; Together Make a Safe, Secure, Robust Platform With a Compelling User Experience | #QtWS22
Qt and QNX; Two Q’s That When Deployed Together, Can Make a Safe, Secure, Robust Platform With a Com...
Watch video
How to build QML apps for webOS and the Qt Creator webOS Plugin
When writing QML applications, one of the most important parts is how to set up your software archit...
Watch video
QtWS17 - Qt Wayland Compositor: Creating multi-process user interface, Johan Helsing, The Qt Company
This talk gives an in-depth presentation of the Qt Wayland Compositor API, showing you how to create...
Watch video
Webinar: Creating Reusable and Scalable UIs with QML
Designing an interactive graphical component for Qt Quick QML is an easy task that can be done in ma...
Watch video
Webinar: Qt for Hypercasual Game Development & Monetization
Watch this interview with Ari Salmi - an experienced software developer and CEO of SnowGrains – a mo...
Watch video
Webinar: Development of Qt based Android Cockpit and Cluster
Watch this Webinar on Development of Qt based Android Cockpit and Cluster
Watch video
Qt Robotic Arm Demo | Industrial Automation | Qt Group
Patrick Thurman, Product Manager at Qt Group walks us through the latest Industrial Automation demo ...
Watch video
Improving the End-to-End Development Workflow for HMI in the Cloud
This is an AWS theatre session talk from CES 2024 by Juhapekka Niemi, SVP of Product Management at Q...
Watch video
Shaper Tools builds CNC machines with Qt
Shaper Tools is shaping up to shape the shapes of the future. Donald Carr talks about how it's possi...
Watch video
How to Create Reusable QML Components Across MCU and MPU Applications?
We explore how we can use Qt tools to create a unified UI for the whole range of your products, from...
Watch video
Qt 6.7 Release - Scale to New Platforms and New Standards
Qt 6.7 focuses on the expansion of supported platforms and industry standards. It also has lots of l...
Watch video
Qt 6.6 Release - Responsive Layouts, Qt Graphs & more
Qt 6.6 simplifies the process of creating complex user interfaces by providing additional higher-lev...
Watch video
Infographic: 5 Tips for Building Scalable and Maintainable Applications
Master Composable Architecture with our infographic, tailored for developers seeking to craft scalable and maintainable software. Discover essential s...
Get Document.webp)
eBook: User Interface Design
This guide will help you navigate the mare magnum of UI software design, with valuable insights from the experience we, at Qt Group, have gained throu...
Get Document
White Paper: Safe and Effective Medical Device Development With Qt
Looking to create powerful, cutting-edge medical devices that are both user-friendly and effective? Check out "Safe and Effective Medical Device Devel...
Get Document
eBook: The Product Manager’s Guide to Analytics
Welcome to "The Product Manager’s Guide to Analytics" - an eBook that will take you on a journey through the world of product analytics. In this eBook...
Get Document
White Paper: UX/UI Megatrends Shaping Today’s World
Welcome to our whitepaper on UX/UI megatrends! In today's fast-paced digital world, it's crucial for businesses to stay ahead of the curve when it com...
Get Document.webp)
Infographic: Code once deploy everywhere – with Limitless Scalability
Check out our infographic to further explore the possibilities of scaling UI development both on the horizontal and vertical axis.
Get Document.webp)
White Paper: Guide to Limitless Scalability
Are you interested in diving deeper into the topic? Download our free guide on Limitless Scalability to learn more and take your UI development to the...
Get Document
eBook: 8 things to know about WebAssembly
New to Qt for WebAssembly? Get this free guide to have a quick eight-question overview of all things related to WebAssembly – what it is, what to buil...
Get Document.webp)
White Paper: User Interface Design for Smart Appliances
Keeping up with the latest trends in user interface (UI) and user experience (UX) development while maintaining a consistent branded look and feel acr...
Get Document
Build and run embedded apps faster from qt creator with docker
Have you ever considered, what it would require to use containers to build and deploy applications to embedded targets? Of course, you have! So, in th...
Get Document
Driving Down Automotive Costs for Richer HMIs with Qt & i.MX RT1170
Automotive HMI solutions traditionally require complicated hardware and extensive architecture to accomplish every goal. In the world of microcontroll...
Get Document
Embracing Qt for Python
Join Qt R&D Manager Cristián and Academy Award Winning software engineer Paul with SilhouetteFX to hear about different use cases, best practices,...
Get Document
White paper: Customer Value Leadership Award for Automotive User Interface/User Experience Software
The Qt Company earns Frost & Sullivan's 2019 Customer Value Leadership Award. Best Practices Award for Automotive UI/UX Frost & Sullivan confi...
Get Document
White paper: Qt vs. HTML5 The Full-Stack Comparison
HTML5 and Qt are both terrific technologies. Choosing one for your next project is challenging. This white paper by sequality software engineering wil...
Get Document
Machine learning meets embedded development
Qt and Ekkono are working together to improve machine learning integration in the embedded development space. Ekkono have their own SDK, built to help...
Get Document
White Paper: Leveraging Human Factors Testing to Develop a Better MedTech Product
Usability and human factors testing are becoming requirements rather than “nice-to-haves” across a wide array of industries that make products we use ...
Get Document
White paper: Migrating Applications from MPUs to MCUs
This white paper shares Verolt Engineering's experience of porting an existing Qt Quick application to a microcontroller (MCU) with Qt for MCUs. They ...
Get Document
White paper: Qt & Android
Witekio performed an unbiased and exhaustive real-life comparison from the point of view of three embedded software development experts by creating a ...
Get Document
White Paper: The Embedded Developers' Guide to Zero Installation
This whitepaper explores how zero installation has evolved to be what it is today, describes the components in a typical solution, outlines specific t...
Get Document
Smarter Products Need Smarter Development
This is a commissioned study conducted by Forrester Consulting on behalf of The Qt Company, published on May 17th 2021. Executive Summary; Digital, co...
Get Document
The Embedded Product Planning and Requirements Guide
How do you approach building a new embedded or IoT device? The legacy method for doing this was relatively straightforward: outline your requirements,...
Get Document
White Paper: The Perfect Framework for Industrial Applications
Requirements for the industrial market now include streamlined design workflows, multiple target deployments, remote browser accessibility, connectivi...
Get Document
Top 10 UI Design Trends and Techniques that will make your products stand out
The User Interface (UI) is more than a platform via which your product interacts with its users and shows them all the awesome stuff it can do. It is ...
Get Document
UI/UX Design Trends in Appliances
The complexity and level of graphical details for home appliances User Interfaces are significantly increasing in the last years. Starting from the an...
Get Document
White paper: Best Practices for a Successful Development Project
In this paper, Qt Professional Services engineering teams share some of the best practices they have found over the years and continue to work by. We ...
Get Document
White paper: Beyond the Code
This whitepaper explores the requirements of UI design for software systems and provides hints, tips and suggestions for anyone tasked with developing...
Get Document
White paper: Building the IoT and How Qt Can Help
This whitepaper defines what the requirements are for developing IoT software, compares frameworks and describes the advantages of using Qt to develop...
Get Document
White paper: Driving the Automotive User Interface
Motor show concept cars have traditionally attracted attention through outrageous body styling, but today’s advanced demonstrators place at least as m...
Get Document
White paper: Forrester Study | The Total Economic Impact™ of Qt for Device Creation
In the race to bring profitable innovation and product improvements to the mass markets for digital user interfaces, pressure grows to reduce costs an...
Get Document
White paper: Functional Safety & Qt
Download our white paper discussing the general requirements for functional safety, how the requirements vary depending on industry and what Qt’s reco...
Get Document.jpg)
White paper: Medical Choosing Commercial Off the Shelf (COTS)
This whitepaper explores the options of choosing a commercial off the shelf software and developing a software from the scratch. The choice may carry ...
Get Document
White paper: Offering for the Medical Industry
This white paper explains how to create FDA- and EU-certified medical systems, how to meet demands of reducing the total costs of ownership (TCO), and...
Get Document
White paper: Qt Conquers the Automotive Interior
This white paper is about the development of today’s sophisticated digital car interiors and why Qt turns out to be the platform of choice. We’ll look...
Get Document
White paper: Qt vs HTML5 #1 Practical Comparison
One man takes 160 hours to create a demo application of an embedded system using Qt & QML and the same number of hours to create the very equivale...
Get Document
White paper: Qt vs HTML5 #2 Million Dollar Question
In this white paper, Burkhard Stubert explains how he could save one of the world’s largest home appliance manufacturers millions of Euros by choosing...
Get Document
White Paper: The Nuts and Bolts of Qt Industrial Applications
If you read our last eBook, The Perfect Framework for Industrial Applications, you may already know that Qt is well suited for building industrial app...
Get Document
White Paper: The Insider's Guide to Excellent UX for the Non-UX People
User experience (UX) is a term you can’t avoid these days. That’s because an excellent UX can more easily provide something that most other facets of ...
Get Document
Companion App Design with Qt
Mobile-based companion applications are becoming ubiquitous, especially within IoT consumer product offerings. Thankfully, the design (and also develo...
Get Document
How are Companies Overcoming the Global Chip Shortage
61 % of decision makers agree that the current semiconductor shortage has negatively impacted their ability to deliver new products, according to a re...
Get Document
How to create a medical device proof of-concept prototype overnight
In the wake of the COVID-19 crisis, the creative technology studio Siili Auto together with The Qt Company, recently launched a new graphical user int...
Get Document
Improve Time to Market for Industrial Edge Devices
Qt and WINSYSTEMS have collaborated to provide an out of box experience on industrial-grade embedded computing platforms that will have you developing...
Get Document
Learn how to addressing medical and industrial challenges with BlackBerry QNX and Qt
The QNX® Neutrino® and its safety variant, the QNX® OS for Safety, are widely regarded as safe and secure operating systems for embedded devices, and ...
Get Document
Meet Qt 6.0
Join Lars Knoll and Tuukka Turunen to learn about the all-new Qt 6 with Q&As. Qt 6 offers you The Productivity Platform for the Future. We want to...
Get Document
Meet Qt Canada
Qt helps develop industry-leading technologies with one line of code at a lower cost and more scalability than ever before. Join us to learn how to go...
Get Document
Qt 6.2 lts vs. qt 5.15 the big feature parity comparison
We have built Qt 6 as the Productivity Platform for the Future to empower Next-Generation 3D/2D User Experiences with Limitless Scalability. In our up...
Get Document
Top 10 User Interface Trends
Top 10 User Interface Trends, in which modern UI designers have been developing & implementing during the 2020 year. The trends we discuss, are ba...
Get Document
Turn your product into a revenue machine with the new Qt Digital Advertising Platform
Qt Digital Advertising enables you to create a new revenue stream for your product by serving ads to your interactive UI application built on the plat...
Get Document.png)
Adapt or Fall Behind: Scalable Solutions Reshaping Manufacturing
From code reusability to decentralized control systems, scalable solutions are not just reshaping manufacturing automation; they're revolutionizing it...
Read more
Precision Planting | Built with Qt
Precision Planting is a leading provider of agriculture technologies that upgrade a farmer’s existing planter, air seeder, drill, sprayer, liquid fert...
Read more
Blue Ctrl | Built with Qt
Blue Ctrl AS develops marine automation systems based on its comprehensive, state-of-the-art X-CONNECT® automation platform. Built entirely on the Qt ...
Read more
Almex | Built with Qt
Almex uses Qt to develop "Mynatouch," a card reader with face recognition that supports online qualification verification.
Read more
Article: Designing Tomorrow - Adopt Apple's Approach to Platform-Centric Standardization
How can you replicate the Apple experience across your products? Central to this challenge is the transition from platform-centric to ecosystem-centri...
Read more
Article: 5 Critical Steps to Enhance UX for Connected Devices
In the age of the Internet of Things (IoT), devices are designed to simplify our lives, improve efficiency, and enhance our overall user experience (U...
Read more
Article: Mastering Composable Architecture: 5 Tips for Success
Master composable architecture with our top 5 tips for streamlined, modular application development. Elevate your coding skills with Qt's expert guide...
Read more




Article: How to Boost Productivity While Managing Technical Debt
Uncover practical strategies to enhance productivity in software development by managing technical debt, meet evolving user expectations, and industry...
Read more
Hasselblad - Built with Qt
A recent example of Hasselblad's technical leadership is the new medium format camera X2D 100C, which uses Qt on all its displays, including Qt for MC...
Read more
ArcGIS Maps SDK for Qt | Built with Qt
Esri is the global market leader in Geographic Information System (GIS) software, location intelligence, and mapping. Read their customer story here.
Read more
Article: Enhancing Automotive UX and HMI Design through Digital Transformation
Digital UX and HMI design are crucial for enhancing the driving experience as the automotive industry evolves. Discover how they are reshaping the int...
Read more
Gruppo Cimbali | Built with Qt
The Qt framework powers La Cimbali's Model S digital display.
Read more.webp)
S3 Fuzion's Xelorate | Built with Qt
Stop searching, start finding with S3 Fuzion's Xelorate.
Read more%20copy.jpg)

Ngine | Built with Qt
Ngine leverages Qt's Digital Advertising solution for their Digital Out of Home platform, Skysignage
Read more
Article: Designing for Efficiency: UX Solutions for Industrial Automation
Boost industrial automation efficiency with UX solutions. Learn how in this expert article from Qt.
Read more
Article: Stay Ahead in Turbulent Times: Unlock the Power of User-Centric UX/UI
Explore the impact of macroeconomic challenges on UI/UX innovation in the embedded systems market. Learn about strong investment in XR, ML, and hyper-...
Read more
Liebherr-Electronics and Drives GmbH - Built with Qt
Qt's framework and components power Liebherr-Elektronik GmbH's Bird's eye and CMS (camera-monitor system) applications.
Read more
RGNT Motorcycles - Built with Qt
RGNT chose Qt as it offers so many effective out-of-the-box solutions for these purposes. In less than a year, a small team of developers was able to ...
Read more
Article: Saving Lives with UX Design
Read why UX's importance in healthcare is growing rapidly and why it's life-saving to pay attention to. Take a look!
Read more
Article: Rethinking UX for the Consumer-Centric Era
This article covers why companies need to level up their UX investments and ensure they are in sync with user behavior in consumer electronics industr...
Read more
Bricsys | Built with Qt
Bricsys is a global provider of the BricsCAD® brand of engineering design software. Learn about their journey and successes using Qt.
Read more
Algebra | Built with Qt
Qt enables Algebra, an innovative technology company, to monetize their embedded device screens with Qt Digital Advertising.
Read more
EM Microelectronic - Built with Qt
EM Microelectronic (Swatch Group) partners with Qt Group to leverage the advanced UI capabilities offered by the Qt framework for the creation of thei...
Read more
AirServer – Universal Screen Mirroring Receiver Built with Qt
AirServer is a cross-platform screen mirroring solution that allows you to project from any Apple, Google or Microsoft device to any TV, monitor or pr...
Read more
AMD – Graphics software
Computing and graphics powerhouse AMD uses Qt in development of its Radeon Software Crimson Edition graphics package.
Read more
Atomic Puzzle by NotskiGames
Read about how NotskiGames, a Finnish mobile game developer, made things easier for themselves by starting to use Qt's Digital Advertising Platform.
Read more
Aurora Net – Cross-Platform Real-Time Sound Reinforcement Control and Management System
Aurora Net boosts the management and monitoring of your sound reinforcement systems into overdrive. Control everything from audio level and temperatur...
Read more
AutoIO – Digital Instrument Clusters
Qt-based anesthesia & critical care medical devices offer superior user experiences with patient safety in focus.
Read more
BEP Marine – Marine Automation Systems
BEP Marine chooses Qt to empower agile development and create user interfaces for their CZone system.
Read more
Bluescape – Collaborative Wall and Workspace Platform
Qt powers the future of visual collaborative workspaces.
Read more
Bosch DruckMessWT – Qt Professional Services Automate Bosch’s Assembly Line Calibration
Qt Professional Services Automate Bosch’s Assembly Line Calibration.
Read more
Velneo — The rapid development environment for enterprise applications and the application engine.
The Low Code Environment for Enterprise Applications, built with Qt.
Read more
BOLT – Electric Motorcycle
The team has built a high-performance all-electric racing motorcycle and used Qt to create its equally powerful dashboard.
Read more
Continental Engineering Services – Digital Instrument Clusters
Together with The Qt Company Continental Engineering Services is providing Automotive OEM’s with high-quality user interfaces.
Read more
IPO.Plan – 4D Planning and Visualization Tool
IPO.Plan ensures maximum added value in complex manufacturing and assembly processes. They offer globally unique planning tools, interactive process v...
Read more
LG – Electronic Smart TVs
LG’s innovative technologies, unique products, and cutting-edge designs are built with Qt.
Read more
M2I – Advanced Automation Systems Built with Qt
Qt powers the high tech core equipment for advanced automation systems.
Read more
Medec – Anesthesia & Critical Care Medical Devices
Qt-based anesthesia & critical care medical devices offer superior user experiences with patient safety in focus.
Read more
Rimac Automobili – Car Infotainment System
Discover how Rimac Automobili used Qt to build a premium car HMI. Automotive software development and hardware development is best with Qt.
Read more
Clarius – Ultra-portable ultrasound scanners Built with Qt
Learn about the pocket sized range of ultrasound scanners shaking up the medical industry, and why they were built with Qt.
Read more
DCC Labs – Set-Top Box
Qt Cuts DCC Labs' Cut Development Time in Half by Boosting Graphics Performance and UI Prototyping Speed.
Read more
Devinco – Admin without Paperwork
Devinco's well-established mobile apps Built with Qt take all the hassle and paperwork out of the delivery and transportation business. Their newest a...
Read more
Dubler – Vochlea's real-time voice-to-midi controller Built with Qt
Dubler is a software for musicians. It tracks the pitch, envelope, and timbre of your voice to let you vocally control effects, expression & pitch...
Read more
Etipack's Reliable Labeling and Coding Systems
Etipack designs, manufactures, and sells labeling and coding systems. They use Qt inside their machines to create the human-machine interface.
Read more
Evoca Group – Smooth Coffee Machine UI
Witekio Helps Evoca Group Re-Engineer Their Top-of-the-Line Vending Machines.
Read more
EyeTech Digital Systems – Eye Tracking and Image Processing
The company’s embedded smart tracker technology powers assistive technology and various embedded OEM applications, including speech devices for the di...
Read more
Eykona – 3D Wound Imaging
Qt-based anesthesia & critical care medical devices offer superior user experiences with patient safety in focus.
Read more
Firstbeat Sports built with Qt
Firstbeat Sports provides holistic physiological performance insights to make informed coaching decisions and maximize the team's performance potentia...
Read more
fman – The Cross-Platform, Dual-Pane File Manager that Makes You Faster!
fman – the cross-platform, dual-pane file manager that makes you faster, built with Qt and Python!
Read more
Formlabs – Advanced Desktop 3D Printers
With Qt, Formlabs delivers intuitive and connected 3D printing experience.
Read more
Framery's Happier & More Efficient Workplaces
Qt empowers Framery, the pioneer and the world’s leading manufacturer of soundproof private spaces for solving noise and privacy issues in open office...
Read more
Gimasi – IoT-Powered Digital Signage
Digital signs are everywhere. They're signpost screens in museums, menu displays in restaurants, or animated advertisement billboards in retail stores...
Read more
GLP Systems – A Breakthrough Development in Laboratory Automation
GLP Systems chose Qt because of the comprehensive & highly intuitive APIs, modularized C++ libraries, declarative programming technology, and tool...
Read more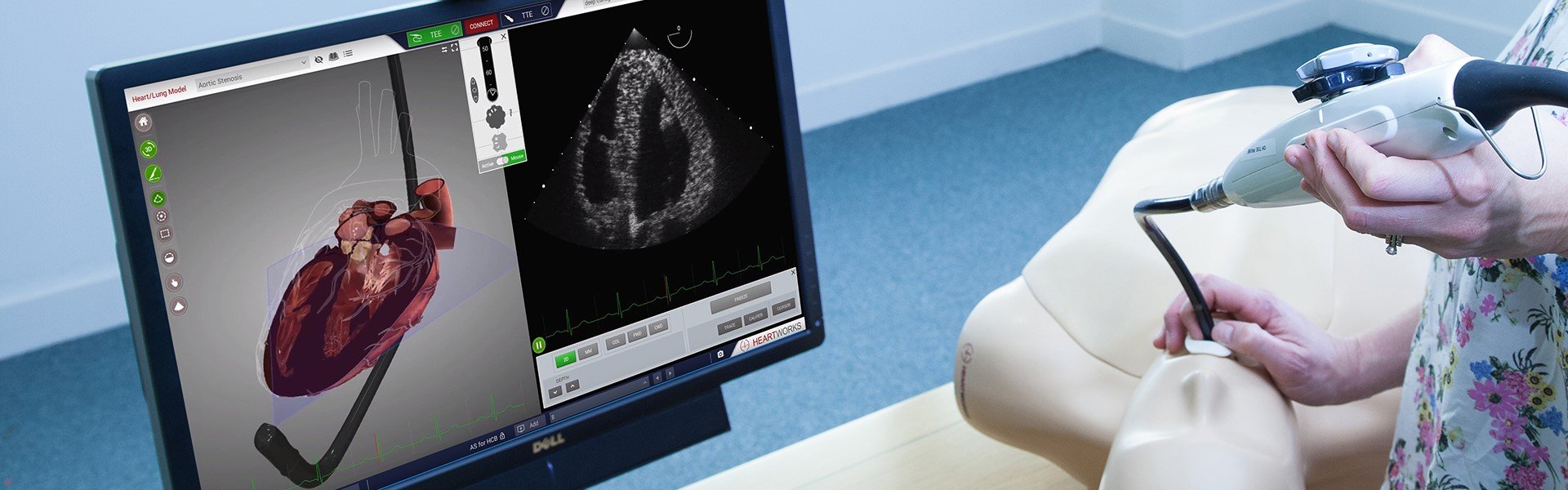
HeartWorks — Training doctors to diagnose heart conditions with world's most accurate 3D virtual heart.
HeartWorks is an ultrasound simulator that uses a computer, a mannequin & 2 ultrasound probes used for teaching cardiac anatomy & echocardiogr...
Read more
Hiri – Enterprise E-mail
Hiri, the best email client for Managers on Windows, Mac, and Linux is built with Qt.
Read more
Imaginando – Polyphonic Synthesizer
Combining Music Technology to Create Inspiring Musical Experiences with Qt.
Read more
Introduction to Qt Creator
Qt Creator IDE 101 – Qt Creator is a complete integrated development environment (IDE) for creating applications with the Qt application framework.
Read more
News: Koenigsegg – Record-Breaking Supercars Built with Qt
Koenigsegg used Qt's complete toolkit and Professional Services to create the ultimate high-performing automotive software.
Read more
Lytro – Light Field Imaging Platform
Enabling the touch-control user interface for Lytro’s new light field cameras.
Read more
Gamry Instruments — Market Leader in Electrochemical Instrumentation Teams up with Qt Service Engineers
Market Leader in Electrochemical Research Teams up with Qt Service Engineers.
Read more
MerlinCryption – Security Encryption Tech
MerlinCryption builds advanced encryption, machine-to-machine authentication, and a patented random data generator, which solve cyber security's tough...
Read more
Navico – Marine Navigation & Information System
Navico uses Qt for Lowrance HDS marine electronics range.
Read more
Neocis Dental Robots
Qt empowers Neocis, a dental robotics company, to modernize their UI and make their operation truly cross-platform.
Read more
Novatron Is Bringing Heavy Machinery Into the Digital Era
Read about how Novatron, a technology company focused on earthmoving automation, simplified their UI/UX operations with the help of Qt's framework.
Read more
Panasonic Avionics – Inflight Infotainment
Panasonic Avionics Inflight Entertainment used Qt to develop Inflight Entertainment systems experienced by over five million passengers every day.
Read more
Parker Hannifin – Parker Application Designer
Parker Hannifin has created a tool based on Qt allowing OEMs to consolidate a machine's UIs into one single display.
Read more
Produce Great Quality Work In Less Time With Zenreader
Qt's framework and components power Zenreader, a new tool for collecting and extracting knowledge efficiently whilst retaining the quality of work.
Read more
eyeMaps – Augmented Reality 3D Maps App
Start-up company, eyeMaps, built with Qt to quickly design an augmented reality 3D maps app for iOS & Android. Qt has great documentation & is...
Read more
Savonlinja – The Digital Transformation of the Most Enjoyable Bus Company
With their industry at a turning point, they had to make big changes and replace old procedures with innovations to stay ahead of the competition.
Read more
Scalable and Adaptable Inflight Entertainment System - Innov8Cabin Solutions
Scalable and adaptable inflight entertainment system. Witekio acted as the co-pilot of this new innovative inflight entertainment system - Innov8Cabin...
Read more
Smasher: Invasion by Forfiction Mobile
Learn how Forfiction Mobile took their game to the next level with the help of Qt's Advertising Platform.
Read more
Tableau – Business Intelligence and Analytics
Using Qt, the business intelligence and analytics leader has changed the way people use data.
Read more
Ubuntu – Linux Distro
Ubuntu is a single, fully maintained OS that runs across a whole family of personal computing form factors and Qt is at the heart of the Ubuntu's UI f...
Read more
Ulstein – Ship Automation System
Read how Qt brings Ulstein’s daring & industry disruptive vision to reality.
Read more
User Experience Design for Software Engineers, ICS & The Qt Company
This webinar is an introduction to User Experience (UX) design, specifically focusing on issues that software engineers encounter.
Read more
Veriskin – Skin Cancer Diagnostics Device
Witekio Uses Qt to help Veriskin Fight Skin Cancer with a Lightning-Fast and Low-Cost Skin Cancer Diagnostics Device
Read more
Contex – Large Format Imaging Scanners
World’s largest developer of large format imaging solutions uses cross-platform Qt to stay ahead of the game.
Read more

Zühlke – Digital Laser Control
Zühlke Engineering helps enable rapid development of low noise digital laser control.
Read more
Convince Your Boss: 10 Reasons to Make Them Say "Yes!" {Presentation}
Are you interested in using Qt but are struggling to find the numbers or facts to make a proper business case for your boss? Then we have just the thi...
Read more
Modern microcontroller (mcu) application development with qt
Qt for MCUs is a complete graphics framework and toolkit with everything you need to design, develop, and deploy GUIs on MCUs.
Read more


Harness The Power of Algorithmic Trading with Volven
Qt's framework and components power Volven, a trading platform with sophisticated algorithms specially designed for the crypto market.
Read more